ずいぶん前に手持ちの中国語辞書データを提供する件で某社に出向いたことがあります。まだ北辞郎をつくる前の話で、手持ちのデータも5~6万語くらいの規模だったと記憶しています。いろいろ話をして、結局データ提供の件は流れたのですが、「もう少し例文が充実しているといいんだけど」というような意見があり、なるほどそれはもっともな話だ、いつか例文の充実を図ろう、そんな決意を胸に私は帰路についたのでした。
そして橋の下を多くの水が流れ、北辞郎が生まれ、今日にいたります。データは辞典幇メンバーのみなさまにより日々登録・修正・加筆されていますが、やはり一般的な辞書には例文の数量で及びません。単語に応じた適切な例文を探してきて、分かりやすい訳を付けるというのはとても手間がかかります。そうそう簡単に数を増やせるものではありません。
この例文についてぼんやり考えているときに思いついたのが対訳データベースです。オンライン上には各種法律、国際標準、条約など著作権の対象にならないデータ、すでに著作権が切れた小説などのデータがあり、そうしたデータの中には中国語と日本語が揃っているものがあります。そのデータを整形してデータベースに登録すれば、たとえば中国語の単語を検索することで、その単語がどのように使われ、どのように訳されているのかを生きた用例の中から確認することができます。市販の辞書に収載されている例文の中には首をかしげるようなものもありますが、このようにして構築した対訳データであれば、実際に使われている例なので信頼性も担保されます。
問題は、対訳コーパスの構築にかかる手間です。例文をひとつひとつ登録することを考えれば、負担はずっと少ないのですが、中国語で1文になっていても日本語では2文に訳出されているケースやその逆のケースもありますので、エクセルのA列に中国語、B列に日本語のデータをコピペして一丁上がりというわけにはいきません。まず句点などを目印に中国語と日本語のテキストを1文1文に分割し、それぞれの対応関係を眺めながら、中国語のデータを結合したり、日本語のデータを結合したりしていかなければなりません。
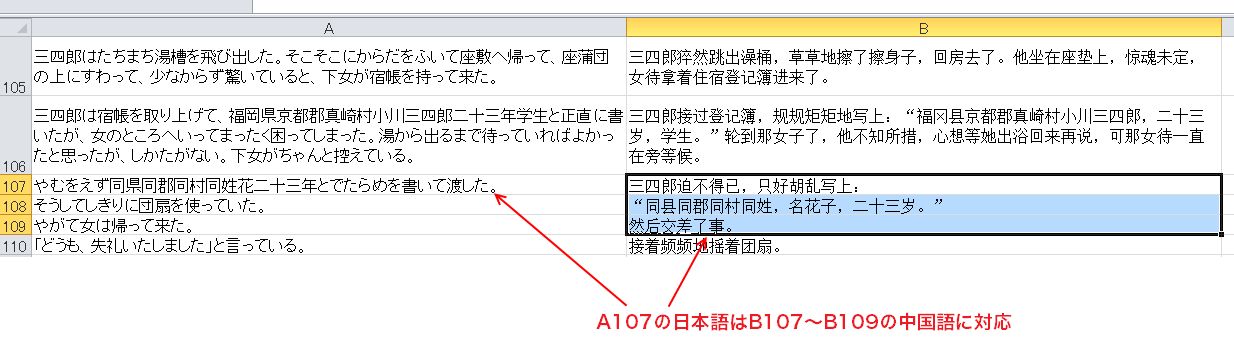
たとえば中国語の入力されているセルA1のデータが、日本語のセルB1~B3のデータに対応している場合、セルB1~B3の値を結合してB1に入力し、B2とB3は削除して上に詰める、という作業を延々と繰り返すことになります。実際、この作業を少しやってみたのですが、あんまり面倒臭いので次のようなエクセルマクロを作りました。
Sub SelectConcatClear()
Dim str As String, c As Range, sr As Long, sc As Long, er As Long, ec As Long
sr = Selection(1).Row + 1
sc = Selection(1).Column
er = Selection(Selection.Count).Row
ec = Selection(Selection.Count).Column
For Each c In Selection
str = str & c.Value
Next c
Selection.ClearContents
Selection(1).Value = str
Range(Cells(sr, sc), Cells(er, ec)).Delete Shift:=xlShiftUp
End Sub
上述した「B1~B3の値を結合してB1に入力し、B2とB3は削除して上に詰める」というステップを1回で行うためのマクロです。エクセルのマクロはほとんど触ったことがないので、たぶんもっといい書き方があると思いますが、とりあえず期待した動作にはなっているので良しとします。
このマクロで多少楽になったとはいえ、ちょっとしたデータなら数千行は当たり前なので道のりの長さにちょっとめまいが(;´Д`)
まあそれでも私はこういう作業が比較的好きなので少しずつ石を積んでいこうと思います(翻訳の勉強にもなります)。先日読んだ堀江貴文氏の「ゼロ―――なにもない自分に小さなイチを足していく」に、誰だって初めは0なんだからかけ算しようとしないで、まずはひとつずつ足し算をしていきましょう、というようなことが書いてあり、ひざを打ったことですし。

ある程度データが揃ったら、北辞郎からこの対訳データベースのデータをひっぱれるようにします。少し前に書いた代筆ツールも対訳データを必要としますし、データベースができれば対訳の読み物を提供したり、翻訳メモリのように使うこともできるので、そのへんを妄想しつつ地道な作業に没頭。